Ensuring Reliable Science from Platform A/B Test Archives - an Update to the Upworthy Archive
J. Nathan Matias, Assistant Professor, Cornell University: co-lead (ongoing contact)
How can we ensure that research based on archives of corporate A/B tests constitutes reliable science?
That’s a question that our team (me, Marianne Aubin Le Quéré, and Kevin Munger) recently found ourselves asking when we discovered data problems in an archive of tens of thousands of A/B tests that we published together with the media organization Upworthy in 2021.

Starting in 2018, the three of us worked with Upworthy, which was famous for conducting A/B tests on headlines, to archive, document, and publish over thirty-two thousand behavioral studies conducted over more than two years. We think it may still be the largest open archive of randomized trials in the social sciences. Since we published the archive in Scientific Data, dozens of researchers have worked with the data, incorporating it into leading scientific studies, textbooks, and fundamental work in statistics.
We found possible issues with 22% of the A/B tests, but thankfully, no published scientific findings have been materially affected to our knowledge
A year ago, one of those scientists contacted us about an anomaly he had noticed—possible evidence that some of the A/B tests might not have been randomly assigned as we had assumed. If true, this could be huge—and might unravel the science that relied on the archive. This post is the story of how we investigated the issue, alerted scientists about the problems, and collectively re-analyzed our research. We found possible issues with 22% of the A/B tests, but thankfully, no findings have been materially affected.
As governments consider mandating that companies release their A/B test archives for transparency purposes, the post also offers lessons for platforms, policymakers, and those seeking to make use of data from experiments they did not conduct personally.
Finding an Anomaly in the Upworthy Archive
Just over a year ago, a scholar contacted us about a sample ratio mismatch (an imbalance in the number of impressions per arm) in some experiments in the study (see Fabijan et al 2019). This might occur where experiments in the dataset were not truly randomized — though the analysis can’t prove it either way.
When preparing the archive, we interviewed engineers, looked at the code that generated random assignments, and ran simulations. But ultimately, we weren’t the ones who had done the experiments, so we couldn’t be completely sure they were fine. When we were alerted to possible issues, we revisited the data, looked again at the code, and called up our sources who used to work at Upworthy to check one more time.
Upon plotting experiments that seemed especially at risk of a sample ratio mismatch, we saw a clear pattern that made us think there could be an underlying technical issue that started in June 2013 and was solved by engineers in January 2014. When we spoke to those engineers, they couldn’t point to a specific memory or code change that could have caused this. But they did offer a theory that might explain it: the server cache.
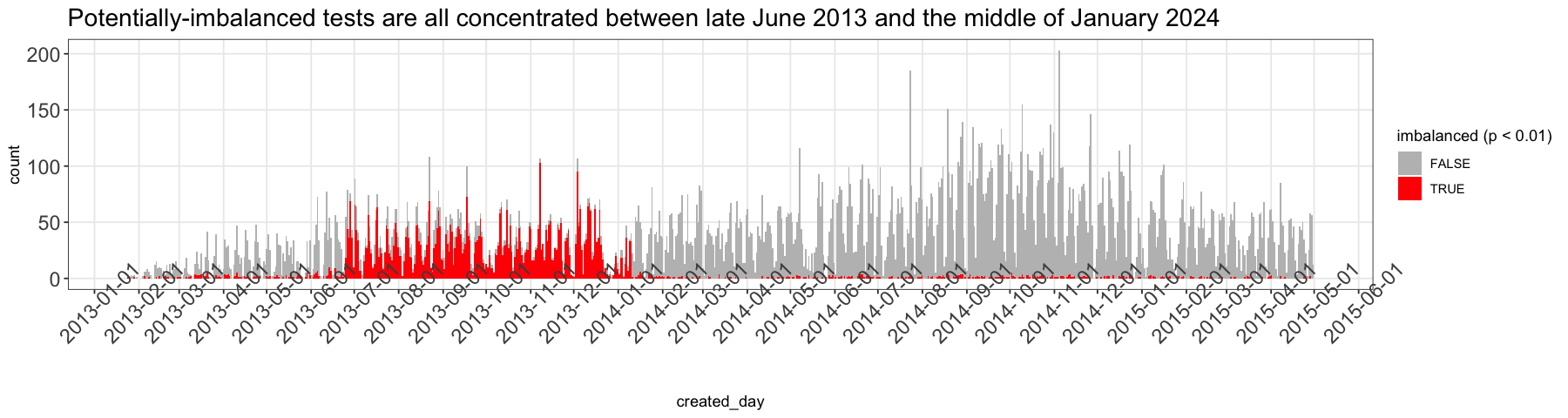
Our best guess is that on June 25 in 2013, Upworthy experienced a configuration glitch in the Cloudflare cache that they used to manage large bursts in viewership. We think this cache queried the Upworthy website and instead of loading N versions of each page, one for each arm of an experiment, it just loaded one arm and showed that one arm to people until the cache expired. Then when the cache reloaded, viewers got the next arm, etc. Since the cache was a third party service, we would never have seen the problem in any code retained by Upworthy and shown to us when creating the archive.
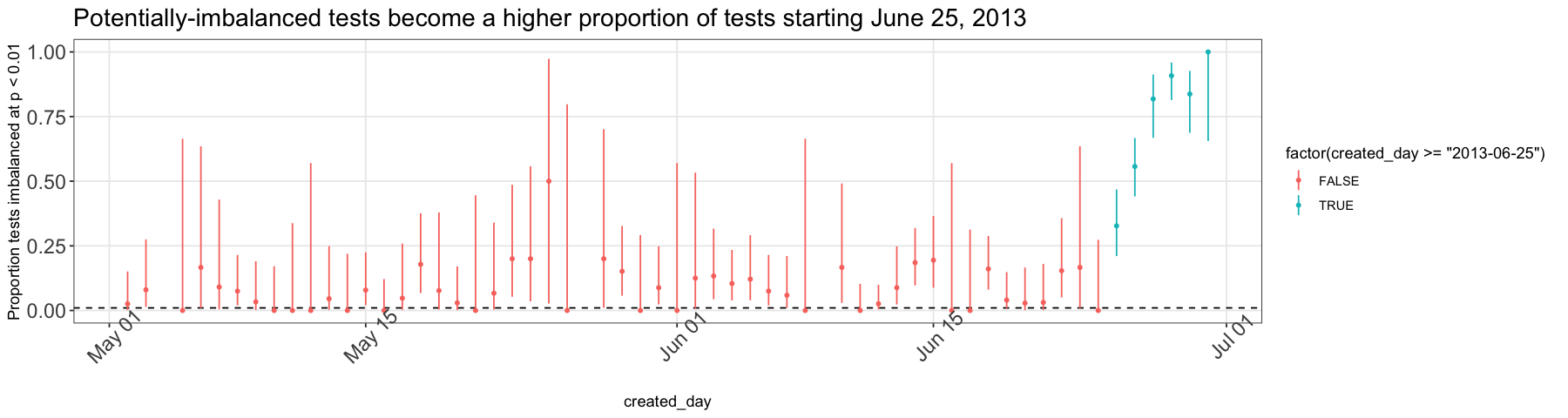
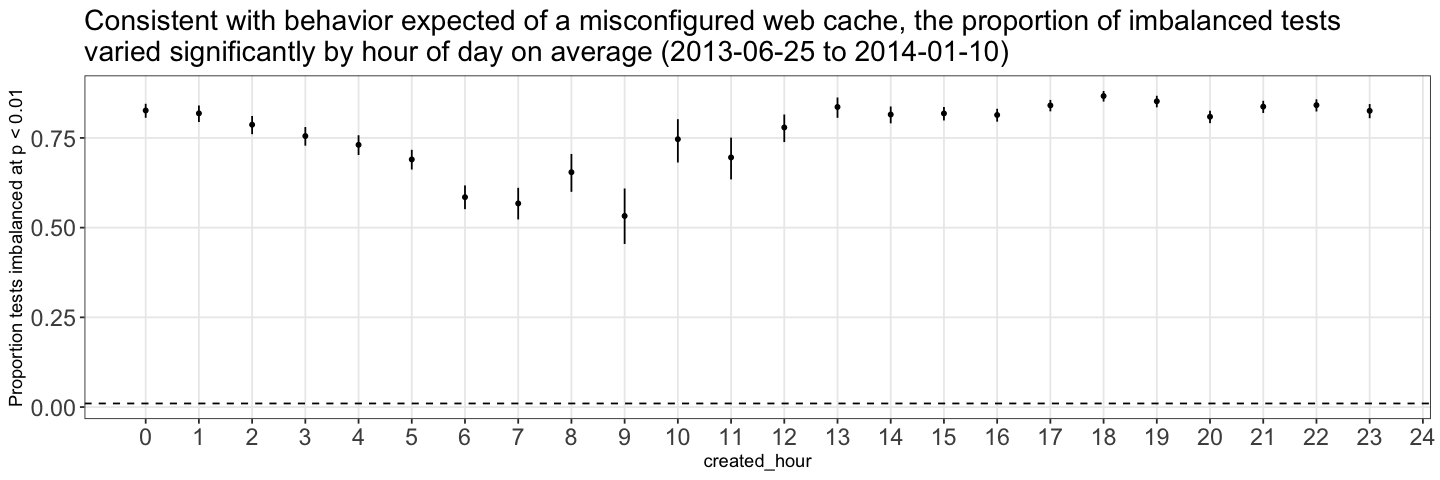
What would we expect to see in the data if there’s a cache issue? The result would look more like block randomization over time periods than individual assignment. If this were true, any article published closer or further away from the cache expiration time would have a higher or lower chance of imbalanced experiment arms. This is exactly what we see in a chart of experiment imbalance plotted against the hour of the day that an experiment was published— imbalance is clearly not distributed randomly across time.
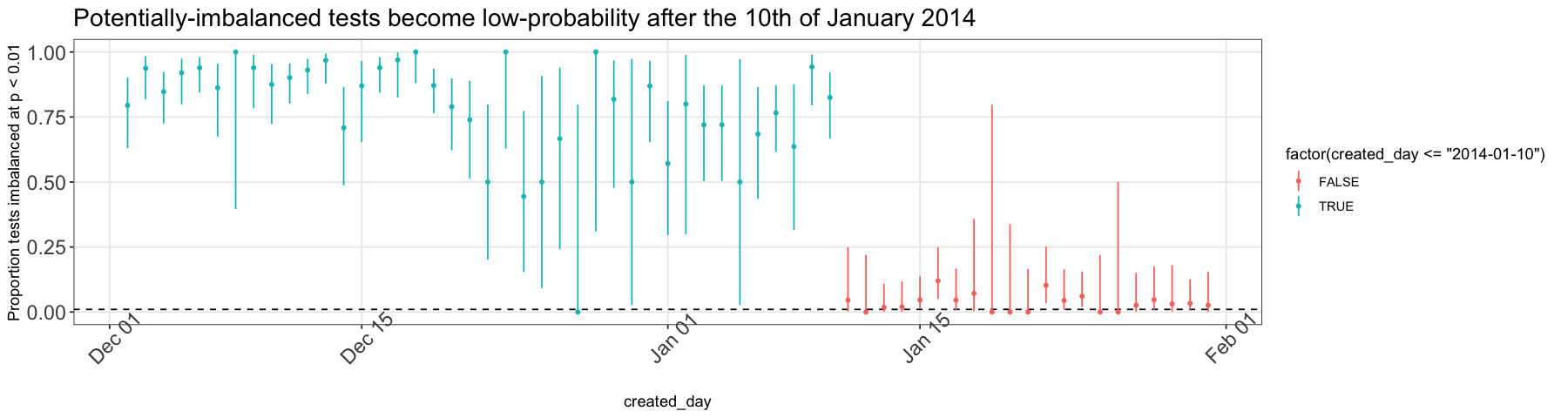
Overall, while we can’t conclusively say that experiments from June 25, 2013 to January 10, 2014 were not truly randomly assigned at an individual level, we think it’s likely that a caching issue caused assignment to be something other than random during that period. As a result, we discourage people from doing statistical research about cause and effect from this portion of the Archive. The records are still a useful record of what Upworthy published, for all other research purposes.
Updating Our Paper
Based on this information, the three of us have worked with Scientific Data to update our paper and the Upworthy Archive. We have taken the following steps:
-
Updated the text of the paper to explain the issue, how we validated it, and what our recommendations for researchers are
-
Added supplementary materials with full details of our analysis
-
Updated the dataset to include a new column indicating experiments that we’re not confident have reliable randomization
-
Updated the Archive webpage to reflect these changes
Revisiting the Scientific Record
Once we had confirmed the problem, we immediately contacted the seven teams of scientists who had published causal research based on the archive and alerted them to the issue. These teams generously re-ran their analyses in ways that omitted potentially-flawed experiments. Thankfully, none of the findings were materially affected — likely because the problem A/B tests were only 22% of the experiments in the full archive.
In the appendix of this post, teams have included a sentence or two with what they found:
Why This Update is a Win for Science
When teaching science, we tell our students that the most reliable findings are ones that have been reproduced repeatedly. Before the existence of projects like the Upworthy Archive, we largely taught this as a theoretical idea. As a recent article in The American Statistician points out, our archive is one of the only very large datasets of social and behavioral experiments ever to be released. By discovering this glitch, we had a chance to see if what we teach in theory would be true in practice.
Our story had a happy ending, but the next A/B test archive could just as easily pollute the scientific record as improve it
I’m confident that every research team re-visited their analysis with the willingness to update their conclusions if their results were substantially influenced by the glitch in Upworthy’s cache. Yet statistically speaking, any meaningful finding that emerged from more than twenty-five thousand experiments would be hard to overturn with just a few thousand more. Science is the search for repeatable knowledge, and when you use statistical techniques designed to reveal repeatable knowledge, they can survive problems like this one.
On the whole, we see this glitch as a validation of the overall model of A/B test archives in open science. With just one archive, the Upworthy Archive has supported substantial contributions to statistics, political science, information science, research ethics, generative AI, and linguistics. And when an issue was discovered, the scientific community mobilized to validate the problem, update our papers, and report the results.
Lessons for Future Releases of Experiment Archives
The Upworthy Archive is likely just the first of a new collection of A/B testing archives that we can expect in coming years. In Europe, regulators are debating whether the Digital Services Act might require companies to release their A/B testing archives. And when a new law comes into effect in Minnesota in 2025, tech firms will be required to release their A/B test archives for public scrutiny in ways that protect privacy.
efforts to routinely publish A/B testing archives should also invest in the resources to carefully document and validate the reliability of those archives
Whether organizations voluntarily publish their archives or regulators for them to do so, the lesson of the Upworthy Archive is that they can make significant contributions to society and to science. But just as with any records, we should trust but verify. Our story had a happy ending, but the next A/B test archive could just as easily pollute the scientific record as improve it.
Software and data errors can undermine the validity of the experiments, even if engineers, data scientists, and managers were unaware at the time of underlying problems. For that reason, efforts to routinely publish A/B testing archives should also invest in the resources to carefully document and validate those archives.
Acknowledgements
We are very grateful to Dean Eckles and Garrett Johnson for raising initial concerns and helping us conceptualize the problem— as well as former Upworthy head of Data & Analytics Daniel Mintz for yet again taking the time to help understand Upworthy’s historical systems. We are also grateful to the teams of scientists who graciously and generously fielded our notification that there could be problems in the dataset: everyone showed a beautiful commitment to getting the scientific record right even if it wasn’t convenient to re-tread projects they thought were finished. We are especially grateful to all of the research software engineers who have created toolsets and libraries for reproducible code and data that saved all our teams months of work. We are also grateful to Guy Jones at Scientific Data for working with us to make the update to our original paper.
Neither the Upworthy Archive project nor the re-analysis had any funders. We are grateful to everyone for doing this unpaid work to strengthen the scientific record — and we continue to seek funding models for developing and maintaining A/B testing archives like the Upworthy Archive that could very substantially advance science as a byproduct of corporate experimentation.
Results of Paper Re-Analyses
We invited teams that worked on these papers to report the result of re-analyzing their results:
(PLOS ONE) Linguistic effects on news headline success: Evidence from thousands of online field experiments (Registered Report)
In this paper, researchers analyzed 24,333 pairs of comparable headlines and identified the linguistic characteristics impacting headline success. First-person singular, third-person singular, and third-person plural pronouns increase the click-through rate, while first-person plural pronouns decrease it. Negative emotion words, indefinite articles, and headline length also increase the click-through rate. After re-running the analysis only with A/B tests that we are confident are reliable, the authors found no differences. The results were nearly indistinguishable.
(Nature Human Behavior) Negativity drives online news consumption
In this paper, researchers analyzed N = 22,743 A/B tests and found negative words in news headlines increased consumption rates (and positive words decreased consumption rates). After re-running the analysis only with A/B tests that we are confident are reliable, all of the results from the main paper were robust and the findings were nearly identical in all respects. For transparency, the authors have included updated results in the supplementary file linked here.
Other teams that also checked their results and found no change
-
Gligorić, K., Lifchits, G., West, R., & Anderson, A. (2021). Linguistic effects on news headline success: Evidence from thousands of online field experiments (Registered Report Protocol). Plos one, 16(9), e0257091.
-
Wu, J. J., Mazzuchi, T. A., & Sarkani, S. (2023). Comparison of multi-criteria decision-making methods for online controlled experiments in a launch decision-making framework. Information and Software Technology, 155, 107115.
-
Coey, D., & Hung, K. (2022). Empirical Bayes Selection for Value Maximization. arXiv preprint arXiv:2210.03905.
-
(A registered report currently under second stage review)
References
-
Matias, J., Munger, K., Aubin Le Quere, M., Ebersole, C. (2021) The Upworthy Research Archive, a time series of 32,487 experiments in U.S. media. Scientific Data.
-
Fabijan, A., Gupchup, J., Gupta, S., Omhover, J., Qin, W., Vermeer, L., & Dmitriev, P. (2019, July). Diagnosing sample ratio mismatch in online controlled experiments: a taxonomy and rules of thumb for practitioners. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (pp. 2156-2164).